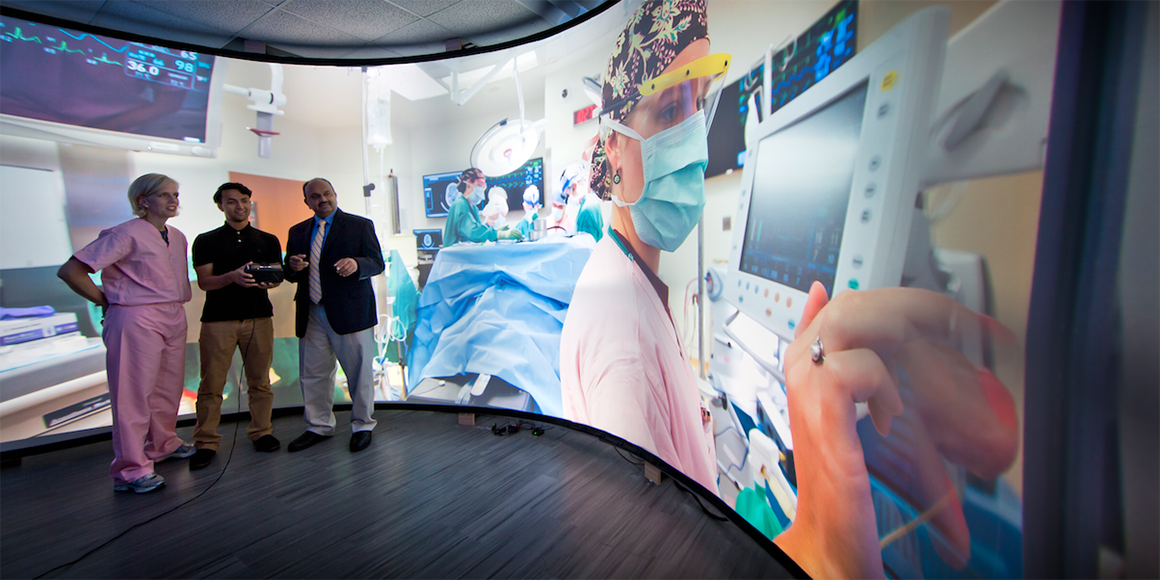
The Future of Virtual and Augmented Reality and Immersive Storytelling
Three speakers at the forefront of innovation in these areas spoke at a University of Maryland program in partnership with The Phillips Collection Read More and Watch Video
FIA Innovation Spark Grant Winners Create the Future of Virtual and Augmented Reality
Watch videos of the team projects and their final presentations
Designing a Research Impact Dashboard: Digging Out of the Acacemic "Trough"
Learn how the FIA-Deutsch Seed Grant Competition changed the academic orientation of one faculty member. Read Now
The Seed Grant Competition Changed My Life
Read how participating in the FIA-Deutsch Seed Grant Competition changed the life of one undergraduate student. Read Now
The Wikid GRRLs Project — Teaching Girls Online Skills
Learn how one of our original FIA-Deutsch Seed Grant Competition winners is continuing to make an impact today. Read Now
Search Workshop
Dan Russell — Google's "director of user happiness" and FIA's Future-ist in Residence — taught a workshop on how to become a power search user and continue down the path of being a lifelong learner. More