These days I find myself searching for data more often…

… if only to reassure myself that there really is a quantifiable perspective on the world. Data isn’t objective, but it’s harder to fake your argument if there’s data to look at and test. Having data gives your argument/discussion a clearer path to clarity.
As you know, Google enjoys data. It enjoys it so much that we’ve made three different ways to find data sets that might be interesting to you. Here they are…
1. Dataset Search. We’ve talked about this new search product before (SRS Jan 24, 2020). It’s a search tool that lets you search for different kinds of data sets. As you can see, a simple search gives pointers to many different datasets, each of which is hosted on the dataset provider’s site.

This is a great way to get the data directly from the source. You can read the original source metadata, release notes, etc.
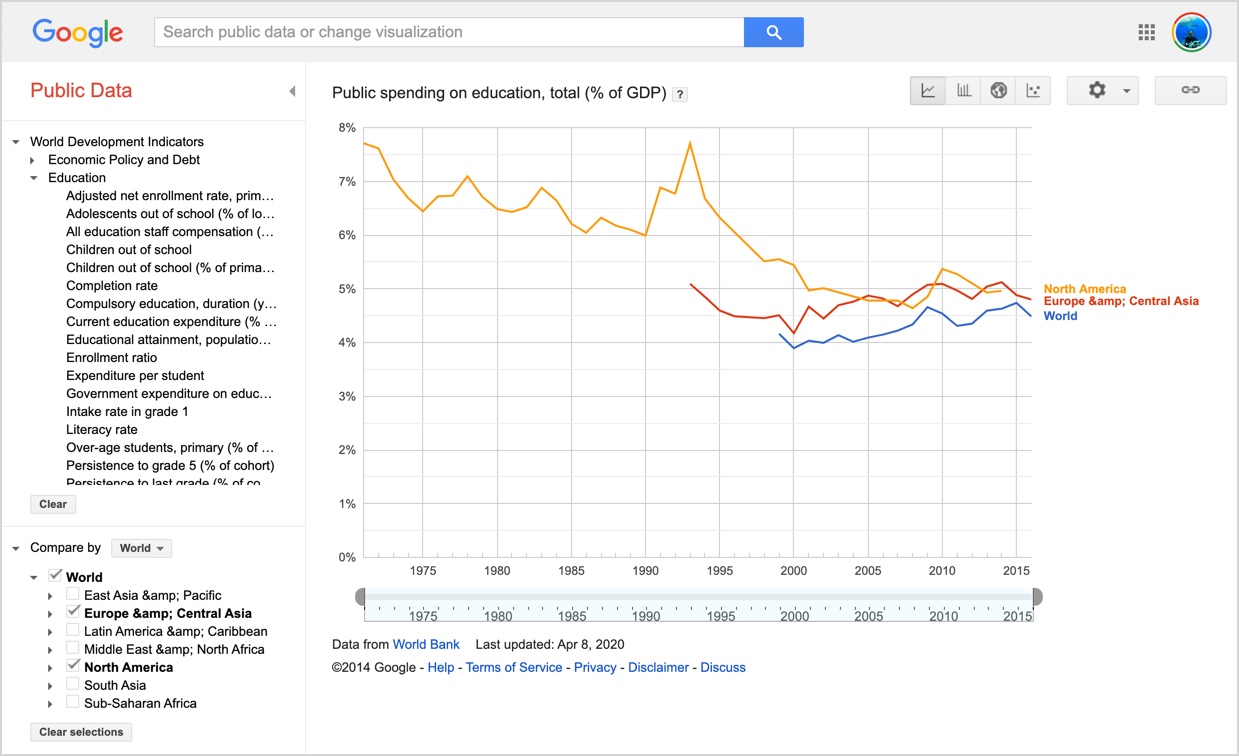
2. Public Data Explorer. We’ve talked about this before as well. (SRS July 3, 2010). It’s a curated collection of data sets from a host of high quality sources. In this case, the data is hosted on Google servers, so even when the host is down (or updated), you can still get to the data.
PDE has a number of data sources you can explore with visualizations, etc. Such as this fairly sobering chart of spending on education over time.
3. Data Commons. The newest data source is the Data Commons project which aggregates a lot of different kind of data sets and provides access to them via APIs and Google Sheets. That is, not only can you look up data, but you can write code that accesses it directly! That is, the Data Commons is an aggregated dataset structured around different kinds of entities: places, people, organizations, etc. All that data is organized into a graph that lets you write fairly straightforward pieces of code (or do specialty searches) to do different kinds of work.
All data is scanned (with permission!) from databases and pulled into the Data Commons graph. You can think of it as facts about those entities, making the resulting dataset a valuable source of combined entity-oriented data.
The data vocabulary used to structure the Data Commons graph builds upon Schema.org, the most widely used vocabulary for structured data on the web, and is documented at schema.datacommons.org.
Here’s a quick example.
Using Google Sheets, I created a sheet and enabled the DataCommons Add-on. Once you do that, you can make a list of different geographical entities. Then you can write a simple Spreadsheet function that pulls data from the DataCommons directly. An example:
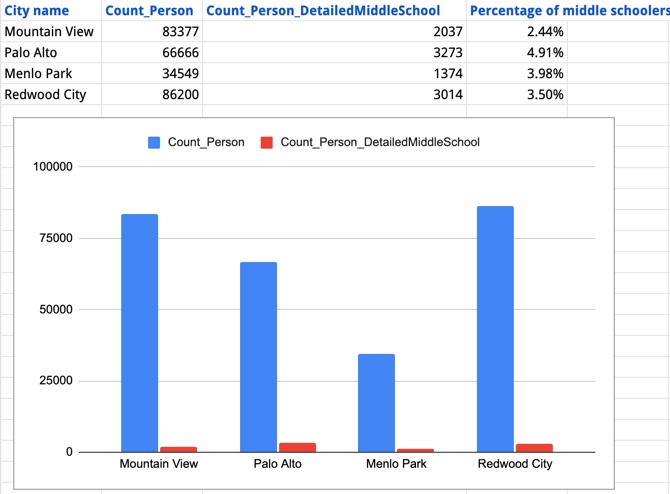
In this spreadsheet, I put the city names in the far left column, then wrote a couple short retrieval expressions and got the population of each city, the number of middle-schoolers in that city, and then computed the percentage of the city’s population that’s in middle-school. This is what those cell expressions look like:
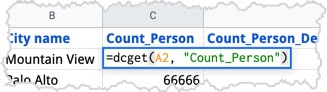
Finally, I made a quick bar chart to show the size of each city’s population and the size of each city’s middle-schoolers. Sweet. (Total time: around 2 minutes.)
So, what’s the difference between these dataset tools? DataCommons is very selective about its sources and about integrating them into the master graph. It goes deep into the data, aggregating many sources and reconciling the different data types (e.g., it integrates BLS data + Census + a few others). By contrast, Dataset Search goes wide, finding datasets about anything anywhere. For breadth, use Dataset Search; for details and single-point-of-access, you want DataCommons.
As you might imagine, this would be really handy for some of our SRS Challenges.
If you’re curious, you can go do this same example by looking at the DataCommons documentation, or you can wait a week (or so) until I get around to posting a Challenge that will need this skillset.
Search on!



