Let’s wrap this up…

Side comment: Why so long between posts? Answer: In addition to my regular gig at Google as a research scientist, I’m ALSO teaching a class at Stanford University on “Human-Computer Interaction & AI/ML” with my friend and colleague Peter Norvig (syllabus). It’s a wonderful experience, but it’s also taking a LOT of time. I always forget how much effort it takes to create a new university-level course from scratch, especially one that’s full of content-rich lectures. Last week (and this week, to be honest) are very full of me writing the course, creating tests, making slides, and organizing the material. Well, it got busy last week, and as you’ll see below, writing up the Wikidata method wasn’t straightforward. Hope you’ll bear with me for the next 7 weeks as we work through the course and write SRS posts. I think I’ll make the next few posts somewhat simpler questions–still very fun–but they shouldn’t take me as much time to write up the answer. The last day of the class is December 15th. I’ll have more time to post more advanced Challenges after that.
As I mentioned last time, there are multiple ways to think about answering this question. Let me show you the Wikidata approach and then summarize.
Reminder: Our Challenge was…
1. Can you find a way to identify other major works of fiction (leaving out fan-fiction for the moment) in which the names of “Starbuck” and “Queequeg” appear (either independently or together)?
Last time we looked at using queries like: [ site:wikipedia.org “starbuck” -starbucks ] to search for all mentions of the word in ALL of Wikipedia. (Noting the use of the minus symbol to remove any mentions of that coffee company.)
My plan was to write up a long post here about how to use Wikidata to search the data underlying Wikipedia to find all mentions of Starbuck or Queequeg in any literary object (books, movies, cartoons, etc.).
So… I spent several hours learning the SPARQL query language for Wikidata and figuring out how to write those queries. Here’s what they look like in the Wikidata SPARQL editor:
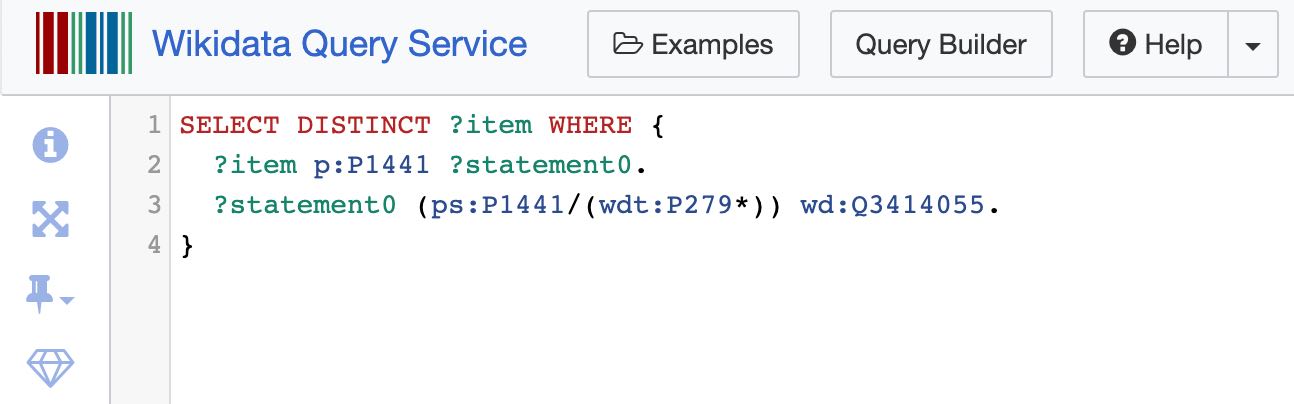
Yeah. In this example the term p:P1441 stands for “is present in work” and wd:Q3414055 stands for “Queequeg.” Roughly, this query translates to “search for everything that has Queequeg present in the work.”
You have to know that “in the work” means, specifically,
“this (fictional or fictionalized) entity or person appears in that work as part of the narration (use P2860 for works citing other works, P361/P1433 for works being part of other works, P1343 for entities described in non-fictional accounts)”
The SPARQL language is very powerful–you can ask nearly anything. If you’d like to learn more about it, here’s the SPARQL tutorial that I used. Using this, you can ask questions like “Who are the grandchildren of Johann Sebastian Bach?” and get answers:


As it happens, I know (because I’m a fan of early music) that JS Bach had 4 grandchildren, not 3: Anna Philippiana Friederica Bach, Wilhelm Friedrich Ernst Bach, Christina Luise Bach, and
Johann Sebastian Altnickol. A fact you can check in many ways, but notably by looking at the Wikipedia page about Bach’s descendents. And this illustrates a problem with the Wikidata; it has entries for everything that’s a first-class object (e.g., famous people), but not everything that’s a piece of text in Wikipedia has an entry in Wikidata. Thus, if you run the SPARQL query for works that contain Queequeg, you’ll get only “first-class items,” such as well-known books, movies, etc… but not all of them. If a book has Queequeg as a character, but the Wikidata doesn’t have an entry for Queequeg in that book, you won’t find it.
That’s not really surprising–every database has a coverage issue. (That is, the database contains only certain types and amounts of information, this is called coverage.) The coverage of Wikidata is less than the full-text of Wikipedia.
It took me a while to figure this out. I was hoping that Wikidata would be more extensive, and allow me to find new entities that simple text search would not–but it didn’t work out that way.



